







May 25, 2026
- Company
- Stories
- Technology
- AI & Robotics
- R&D
- Circular Economy
Oct 15, 2020
Company / Press Releases
Panasonic Corporation and Stanford Vision and Learning Lab (SVL) in the US have compiled the world's largest1 multimodal datasets2 for living space AI development, called Home Action Genome, and make it available to researchers. In addition, the parties host an International Challenge on Compositional and Multimodal Perception (CAMP), a competition for action recognition algorithm development using this dataset.
Home Action Genome is an image and measurement dataset compiled from multiple sensor data, including data from cameras and heat sensors, in residential scenes where daily life actions are mimicked. The data includes annotation3 that characterizes human action content for each scene.
Information concerning data acquisition and CAMP participation methods is available at the CAMP website.
https://camp-workshop.stanford.edu/
Most living space datasets released to date have been small and composed largely of audio and image data. The new dataset combines Panasonic's data measurement technology with annotation expertise from SVL to achieve the world's largest multimodal datasets in living space.
AI researchers will be able to apply this dataset to machine learning, and utilize it for research into AI to support people in the home.
To realize individualized Lifestyle Updates that make living better day by day, Panasonic will accelerate AI development for home by promoting collaborative use of the dataset.
The dataset is composed of 3,500 scenes with multiple location and human subject data in 70 action categories. Each scene consists of sequences with duration of approximately two to five minutes.
| Data type | Detail |
|---|---|
| Video | Camera image data |
| IR | Graphic representation of IR sensor grid-based heat data for humans and objects |
| Audio | Microphone audio data |
| RGB Light | Intensity for red, green, and blue visible light |
| Light | Interior light intensity data |
| Acceleration | Angular speed and acceleration data from gyro sensors and accelerometers |
| Presence | Human presence data from IR sensors |
| Magnet | Geomagnetic sensor data |
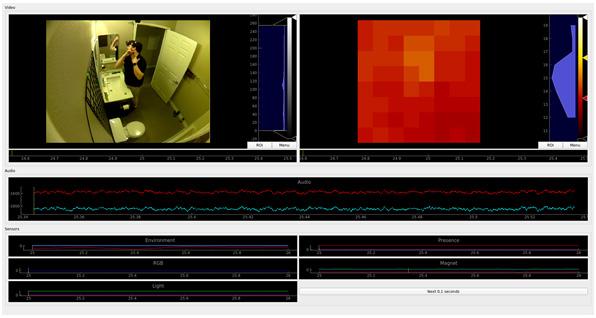
Example of “Shaving" scene image data.
Graphs represent each sensor's data in a time series
The multimodal dataset includes the following information.
Please visit the CAMP website for further information.
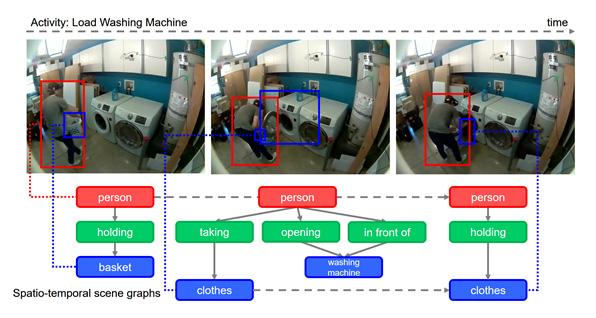
Diagrammatic of annotation example
The content in this website is accurate at the time of publication but may be subject to change without notice.
Please note therefore that these documents may not always contain the most up-to-date information.
Please note that German, Spanish and Chinese versions are machine translations, so the quality and accuracy may vary.














