









Dec 15, 2025
- Company
- Press Releases

Dec 25, 2023
Company / Press Releases
Osaka, Japan – Panasonic Holdings Co., Ltd. (hereinafter referred to as Panasonic HD) has developed an image recognition AI with a new classification algorithm that can handle the multimodal nature of data derived from subject and shooting conditions. Experiments have shown that the recognition accuracy exceeds that of conventional methods.
Image recognition AI recognizes objects by classifying them into categories based on their appearance. However, there are many cases when even objects belonging to the same category, such as “train” or “dog”, are classified under subcategories such as “train type” or “dog breed”, having very different appearances. Furthermore, there are many cases in which the same object can appear to look different due to differences in shooting conditions such as orientation, weather, lighting, or background. It is important to consider how best to deal with such diversity in appearance. In order to improve the accuracy of image recognition, research to this point has been carried out with the aim of achieving robust image recognition that is not affected by diversity, and classification algorithms have been devised to find similarities within subcategories and features common to objects in a given category.
As AI continues to be deployed in a variety of settings and a large number of diverse images are being handled, the limits of the approach of “finding common features” have become apparent. In particular, when there are subcategories with different appearance tendencies within the same category (multimodal distribution), AI often has trouble successfully recognizing such objects as being in the same category, resulting in a decrease in recognition accuracy.
Therefore, our company has focused on taking advantage of differences in appearance and developed a new classification algorithm that captures the diversity of images using a two-dimensional orthonormal matrix. Using a benchmark dataset*1, we demonstrated that it is possible to perform highly accurate image classification even on data with a multimodal distribution, which is difficult for AI.
This technology is a result of the research of REAL-AI*2, the Panasonic Group's AI expert training program, and was accepted to the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2024), a top conference in the computer vision field. A presentation will be made at the plenary conference in Hawaii, USA, which will be held from January 4 to January 8, 2024.
Panasonic HD will promote the research and development of AI technology that accelerates its social implementation while also focusing on training top AI experts.
The applications of image recognition technology are increasing, and the technology is expanding into situations where it has not been used before. As its applications expand beyond areas where it was easier to apply, there is a need to deal with objects in the same category that can appear in a variety of ways, something that conventional AI has difficulty with.
In the conventional deep learning framework, an AI model basically learns that things that look similar belong to the same categories. But in recent years, in order to improve classification performance, it has become common to significantly increase the number of data and variations in appearance during its learning process. This makes it possible to determine that the given objects fall into the same category, even if the objects appears completely different depending on factors like the shooting orientation, lighting, and background. For this reason, attention has been focused on how to have AI successfully learn the essential features that are common to the target objects without being distracted by the variety of appearances contained in large amounts of data.
The distribution of appearances within a category is actually not uniform. Within the same category, there are multiple subcategories with multiple different trends in appearance (multimodal distribution). For example, in the “Birds” category shown in Figure 1, there are groups of images of the same bird with different tendencies, such as “birds flying in the sky”, “birds in the grassland”, “birds perched in trees”, and “bird heads”. Each of these images contains rich information about the object. If we focus on the essential features, we end up throwing away the diverse information that the images contain. Therefore, we have developed an algorithm that actively utilizes information about the various ways in which objects appear to improve AI’s ability to recognize images with multimodal distribution, which is difficult for AI. In order to continuously capture the distribution of features, we expanded the weight vector of the classification model, which has traditionally only been a one-dimensional vector, to a two-dimensional orthonormal matrix. This allows each element of the weight matrix to represent a variation of the image (differing background colors, object orientation, etc.).
As a result of this experiment*1 on a benchmark dataset, this method has shown that it is possible to identify the edge of a group of features that should allow the AI to classify the same object (the star mark indicates the edge of the “bird” category captured by this method) as shown in Figure 1, by introducing a classifier that can continuously capture image features that are included in extremely diverse categories that look like “birds”.
As a result, as shown in Figure 2, even for categories like “bus” and “streetcar”, which are close in appearance and difficult to classify as separate, our algorithm was able to find images that belong to the same category without being confused by other vehicles that look similar.
Due to the algorithm being simple, when adding it to a general deep learning-based image recognition model (ResNet-50), the memory increase is only about 0.1% in practical use (10 classes). It is expected that recognition accuracy and explainability can be improved with only a small increase in memory usage.
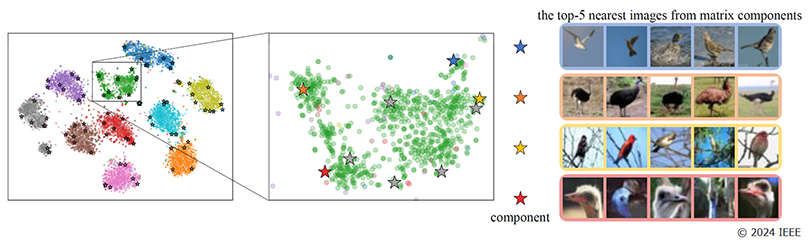
Figure 1 shows image classification results using this method and the weight matrix capable of expressing image variations. For the “Birds” category shown in green in the left figure, images that are similar to each component of the AI model's weight matrix are recognized and displayed in different colors in the right figure. Starting from the top, each row of the weight vector represents an element corresponding to a multimodal peak in the category: flying birds, grassland birds, tree birds, and bird heads. From this, it can be said that the classification model was successfully trained to capture different variations of the same bird category. (Quoted from the accepted paper © 2024 IEEE)

Figure 2 shows the recognition results of the conventional method DNC*3 (left) and the proposed method (right) in the task of querying images from the same category. The first line is a query task for a bus image, the second line is for a train, and the third line is for a streetcar. While the conventional method has been able to find other vehicles that are similar in appearance, the proposed method is able to find images from the same category with a rich variety of appearances. (Quoted from the accepted paper © 2024 IEEE)
This method can perform image recognition that smoothly captures the characteristics of the same object that appears in various ways, which is something that is difficult for conventional AI to accomplish. This is expected to make contributions especially in situations where advanced image understanding is required at sites with a variety of perspectives, such as those relating to mobility, manufacturing, and robotics.
Panasonic HD will continue to accelerate the social implementation of AI technology and promote the research and development of AI technology that will help customers in their daily lives and work.
*1 Classification task for image recognition benchmark dataset CIFAR-10/100, ImageNet.
*2 An in-house research group organized across the entire group to lead the Panasonic Group's cutting-edge AI research and development by fostering top human resources who can quickly deploy cutting-edge technology and create value. Under the guidance of Professor Tadahiro Taniguchi, a professor at Ritsumeikan University and an employee of Panasonic HD, and Professor Takayoshi Yamashita of Chubu University, many members, from young people to experts, took on the challenge of competing at top conferences, and many papers were accepted.
*3 Wang, W., Han, C., Zhou, T. and Liu, D.: Visual Recognition with Deep Nearest Centroids, The Eleventh International Conference on Learning Representations (2023).
https://openaccess.thecvf.com/content/WACV2024/html/Goto_Learning_Intra-Class_Multimodal_Distributions_With_Orthonormal_Matrices_WACV_2024_paper.html
This research is the result of a collaboration between Junpei Goto, Yohei Nakata, Kiyofumi Abe, and Yasunori Ishii of the Panasonic HD Technology Division, and Takayoshi Yamashita, professor at Chubu University, and was conducted under the guidance of experts as part of the Panasonic Group's AI expert training program called REAL-AI.
- WACV 2024 https://wacv2024.thecvf.com/
- Panasonic×AI website https://tech-ai.panasonic.com/en/
|
About the Panasonic Group Founded in 1918, and today a global leader in developing innovative technologies and solutions for wide-ranging applications in the consumer electronics, housing, automotive, industry, communications, and energy sectors worldwide, the Panasonic Group switched to an operating company system on April 1, 2022 with Panasonic Holdings Corporation serving as a holding company and eight companies positioned under its umbrella. The Group reported consolidated net sales of 8,378.9 billion yen for the year ended March 31, 2023. To learn more about the Panasonic Group, please visit: https://holdings.panasonic/global/ |
The content in this website is accurate at the time of publication but may be subject to change without notice.
Please note therefore that these documents may not always contain the most up-to-date information.
Please note that German, Spanish and Chinese versions are machine translations, so the quality and accuracy may vary.




